
Thoughts on autoresearch
Andrej Karpathy’s autoresearch repo has been getting a lot of attention because it frames research as a simple loop: edit a training file, run a fixed five-minute experiment, and keep the change only if val_bpb improves. That kind of concrete objective is exactly why agents like Claude Code can do reasonably well here. By March 10, 2026, the GitHub repo page showed about 20k stars, while the commit history goes back only to March 6, 2026.
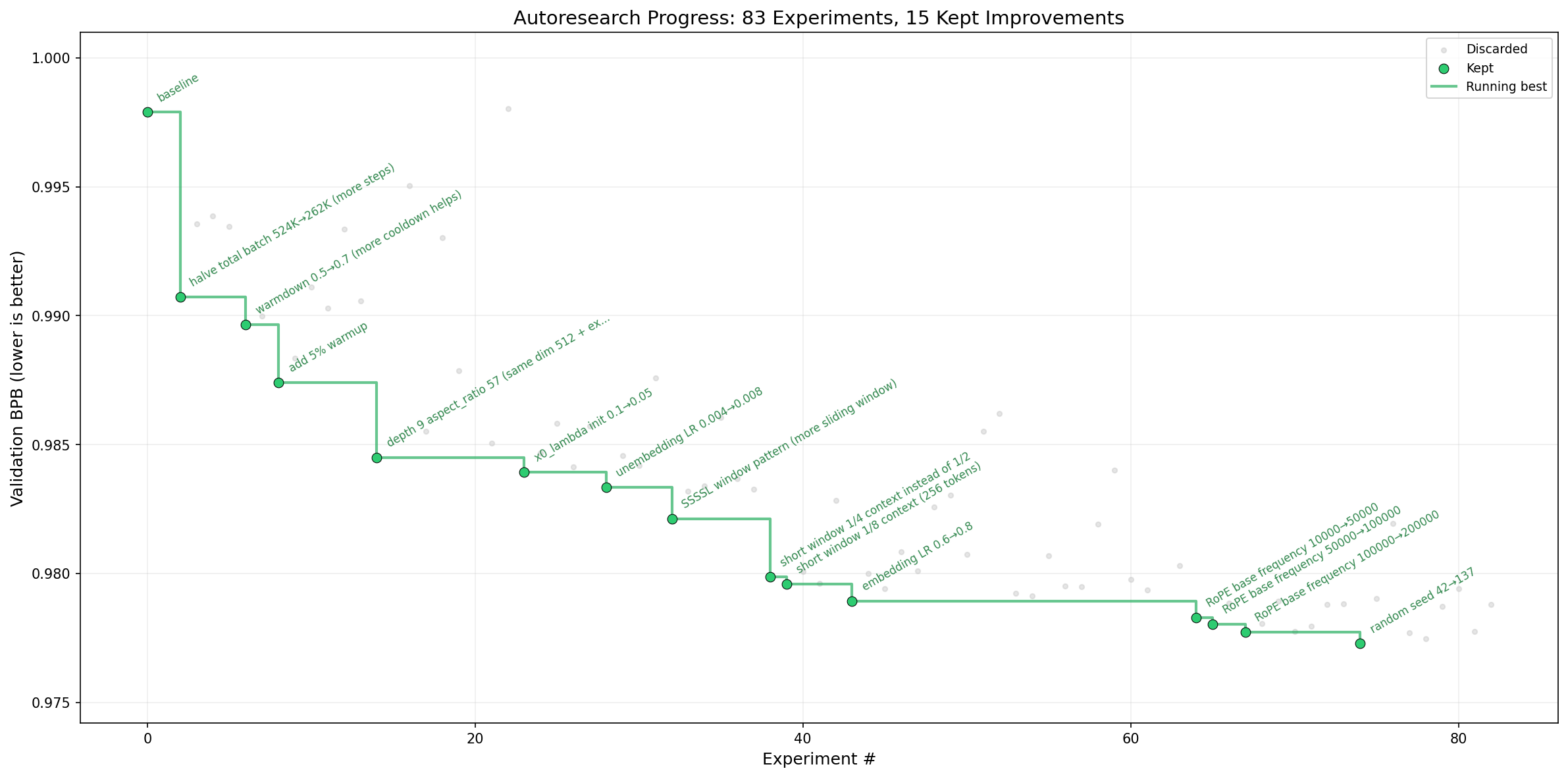
A concrete loop like this is a big part of why the setup feels promising: the agent can try a change, get a verifiable result quickly, and keep iterating.
However, I think a lot of the excitement around autoresearch overstates what is coming from the agent itself. An important part of its success comes from other places as well: having a clear objective, a fast verification loop, and a small setting that still transfers.
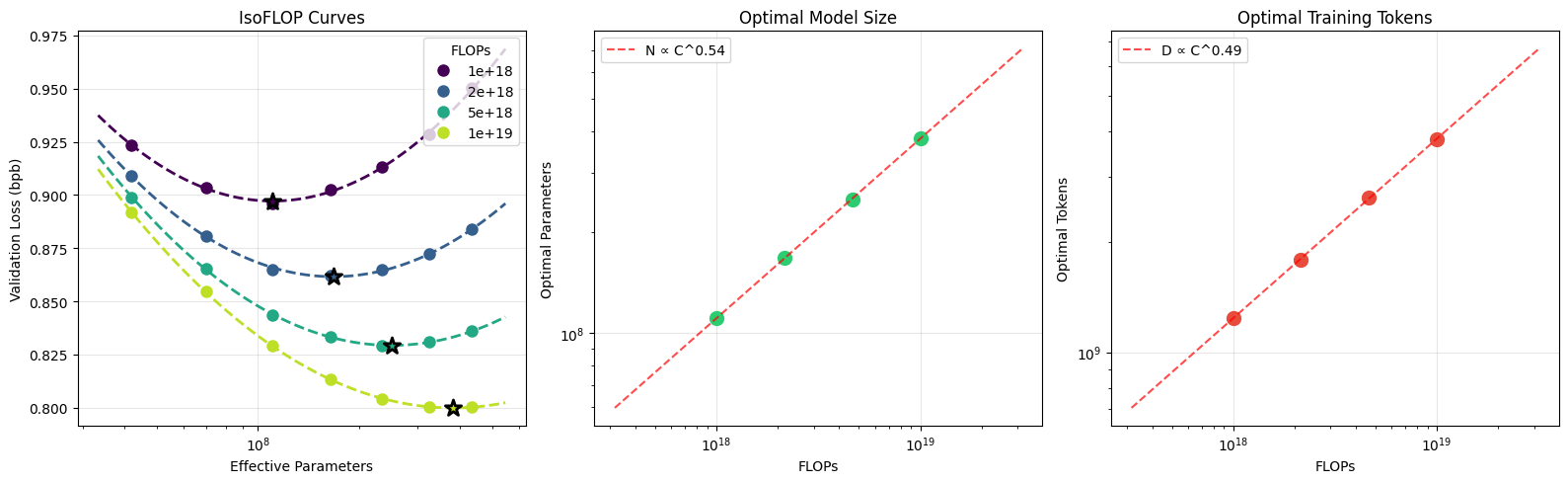
At the same time, I think the success of autoresearch is built on a lot of prior work in turning large and expensive research questions into mini-settings. From nanoGPT to nanochat, Karpathy has spent a lot of effort scaling things down so research can iterate quickly while still maintaining correlation with the larger setting. If you look closely at nanochat, you can see that scaling matters a lot there, because a finding in a minimal setup is only useful if it transfers.
The nanochat repo makes this very explicit with its small-scale scaling-law experiments, and the Jan 7 miniseries discussion gives more context for that direction.
 Another important part is the work that went into building datasets and evaluations that can support this kind of mini-research while preserving transfer to the larger problem. That part matters at least as much as the agent itself.
Another important part is the work that went into building datasets and evaluations that can support this kind of mini-research while preserving transfer to the larger problem. That part matters at least as much as the agent itself.
To me, the hard part is not just being given a research objective. The hard part is taking an objective that is expensive to verify and translating it into a small setting that is fast to verify and iterate on, without losing too much of the chance that success in the small setting transfers back to the original one. This requires insights.
This is also where the bottleneck changes. Before you shrink a costly setting into a small one, the bottleneck is the runtime of the experiment. If one experiment takes two days, then after two days a human still has enough time to analyze the result, read the report, and start the next run. In that case, the main bottleneck is not human productivity. It is experiment cost in time.
But if you shrink that loop from two days to two hours or even two minutes, then the bottleneck starts to become human iteration speed. It is hard for a person to come up with a new idea every two minutes, write the code, run it, and keep going. That is where the value of autoresearch really appears. It reduces the human bottleneck for verifiable tasks that can be iterated quickly, and of course it can keep working while you sleep.
Overall, if you want auto research to work well in your own domain, what matters is that you have a clear objective and, even more importantly, a small-scale setting that your original problem can be transferred into without breaking the signal. If you have that, then research can iterate quickly while you are away, on vacation, or asleep.